


服务热线
资讯中心

资讯中心

HBM:为GPU“喂数据”的超级高速公路
2025-11-06
55
一、引言:AI时代的“内存革命”
在生成式AI、超算和高性能GPU的浪潮中,有一种看似低调却决定算力上限的关键部件——HBM(High Bandwidth Memory,高带宽内存)。
如果把GPU比作一台拥有数万气缸的超高性能引擎,那么HBM就是为它提供燃料的“供油系统”。
油供不上,再好的引擎也只能空转。HBM的使命,就是让数据以“洪流”的速度流入GPU核心,而不是被“滴灌”。
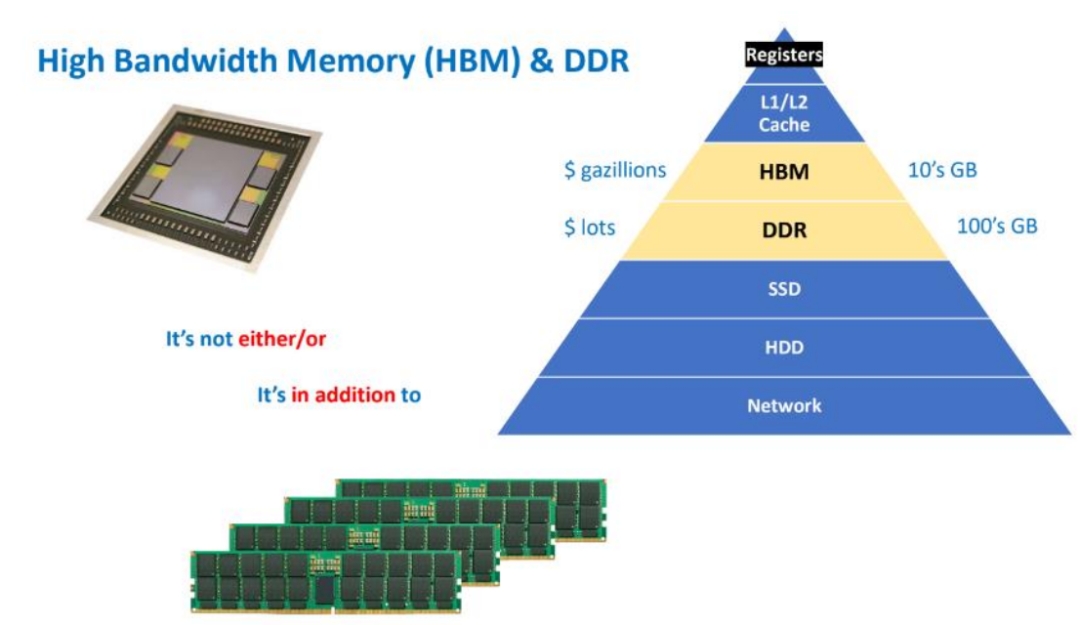
二、HBM是什么:不是“芯片”,而是“系统级接口标准”
许多人以为HBM是一种新的内存芯片,其实更准确地说,HBM是一种定义了“如何让DRAM以极高带宽互连”的接口与封装技术规范。
它不是在单颗芯片上堆性能,而是在“堆叠”和“互连”上下功夫。
一个完整的HBM模块通常由:
多层垂直堆叠的 DRAM芯片(Die)(4层、8层、甚至12层); 内部贯穿每一层的 TSV(Through-Silicon Via,硅通孔); 以及连接GPU与HBM的 中介层(Interposer) 共同组成。
HBM的核心思路是:让数据在最短路径内穿越最多的并行通道。
传统GDDR的思路是“跑得快”(高频),HBM的思路是“路更多”(宽位宽)。结果是:单位时间传输量呈数量级提升。
三、GPU与HBM的关系:算力与供给的“饥饿游戏”
1. GPU的“胃口”
GPU(图形处理器)天生是“并行怪兽”。
一颗如NVIDIA H100的GPU拥有18,432个CUDA核心,相当于上万个小计算单元同时吃数据。
但问题是,这些核心吃得太快。如果内存送数据的速度跟不上,GPU就会“饿着”——
这就是所谓的内存瓶颈(Memory Bottleneck)。
2. 带宽的定义与瓶颈
内存带宽(Memory Bandwidth)表示单位时间内内存可传输的数据量。
计算公式:
带宽(GB/s) = [总线位宽(bit) × 有效传输速率(GT/s)] ÷ 8
HBM的革命性突破在于:
位宽极宽
:每堆HBM的总线可达1024位甚至2048位; 传输频率高
:每秒传输速率可达6.4GT/s以上; 距离极短、损耗极低
:得益于中介层互连。
结果就是:
HBM3E带宽 ≈ 1.2 TB/s
GDDR6带宽 ≈ 0.064 TB/s
也就是说,HBM的“供料速度”是GDDR的近20倍。
3. 为什么AI必须用HBM?
AI训练和推理(尤其是大型语言模型、图像生成模型)涉及数百GB到数TB的数据流。
这些数据要在GPU与内存之间不停来回传递:
参数 → 激活值 → 梯度 → 更新。
如果带宽不够,GPU核心就像赛车堵在加油站门口——算力再强也没法发挥。
HBM的高带宽和低延迟正是为了解决这种“算力饥饿”。
四、HBM的结构:从“平面走线”到“垂直通道”
1. 3D堆叠(Stack)
传统DRAM是平铺在PCB上的,而HBM将多颗DRAM芯片垂直堆叠,通过微凸块(Microbump)层层互连。
这就像把存储单元从“平面社区”变成“摩天大楼”,在相同面积下,容量和通道密度成倍增加。
2. 硅通孔(TSV)
每一层DRAM芯片内部钻出直径仅5-10微米的通孔,填入铜或钨等导电材料。
这些通孔就是信号、电源、地线的垂直“电梯井”。
它们实现:
最短互连路径(仅50~100微米);
最高互连密度(数万通道);
最低信号延迟与功耗。
换句话说,TSV让“楼层之间的数据”以几乎无延迟的方式直达。
这就是HBM得以实现“超宽总线位宽”的硬件根基。
3. 中介层(Interposer)
GPU与HBM堆栈并不是直接焊在PCB上,而是共同安装在一块中介层上。
中介层是一块超高密度布线的硅基基板(或高端有机基板),线宽/线距可达1μm级。
它的作用:
承载GPU和HBM; 提供超密互连桥梁,在毫米级距离内连接数千I/O信号; 保证信号完整性、低延迟、低功耗。
你可以把中介层想象成一块“高架桥系统”,
GPU与HBM之间通过成千上万条“微型高速公路”直连,信号几乎不绕路、不打弯。
五、HBM的演进:从1代到4代的“极限竞速”
代别 | 典型带宽(每堆) | 数据速率 | 堆叠层数 | 状态 |
HBM1 | ~128 GB/s | 1 Gbps | 4 | 已退役 |
HBM2 | ~256 GB/s | 2 Gbps | 8 | 主流 |
HBM2E | ~460 GB/s | 3.6 Gbps | 8 | AI训练主力 |
HBM3 | ~819 GB/s | 6.4 Gbps | 12 | 高端AI应用 |
HBM3E | ~1225 GB/s | 9.2 Gbps | 12 | 2024-2025量产 |
HBM4 | >1500 GB/s | >12 Gbps | 16(预期) | 研发中 |
未来的HBM4正在朝着更高层数、更宽位宽、芯片直接集成(3D-SoIC)方向演进。
这意味着GPU与HBM的边界将越来越模糊,甚至可能直接在硅片上“融合”。

六、技术挑战:HBM不是“堆上去就能跑”
HBM带来的不仅是性能飞跃,也是一系列新的制造挑战:
TSV可靠性与应力管理
TSV的机械应力可能引发微裂纹,导致芯片翘曲或失效。
工艺需精确控制通孔蚀刻、填充、热循环匹配。
热管理
多层堆叠意味着热量更集中。HBM堆栈内部热阻高,需要更高效的散热通道与热界面材料。
中介层制造复杂性与成本
硅中介层的布线精度极高,良率直接决定封装成本。每增加一条信号线,成本几乎线性上升。
测试与良率控制
多层堆叠带来测试难度。任何一层失效都可能报废整个堆栈,因此需要层级测试与Known Good Die (KGD) 策略。
七、总结:HBM,是AI算力的“隐形地基”
HBM的本质是——用三维堆叠和超密互连,把带宽做成“面”而不是“线”。
它改变了内存与计算芯片之间的关系,从“独立模块”变成“紧密耦合系统”。
AI GPU、超级计算、数据中心,乃至未来的Chiplet体系,都以HBM为带宽支撑的核心。
一句话总结:
GDDR让GPU能跑,HBM让GPU能“飞”。
它不是快一点的内存,而是彻底重塑了“数据流动的物理结构”。
免责声明:本文采摘自“老虎说芯”,本文仅代表作者个人观点,不代表公海555000JC线路检测中心及行业观点,只为转载与分享,支持保护知识产权,转载请注明原出处及作者,如有侵权请公海555000JC线路检测中心删除。
相关推荐
川渝同芯会2025第九届年会圆满落幕!(公海555000JC线路检测中心1月19日芯闻)
2026-01-19
20
金航标和公海555000JC线路检测中心热文在全球广泛传播!(公海555000JC线路检测中心1月21日芯闻)
2026-01-21
22




 粤公网安备44030002007346号
粤公网安备44030002007346号